
“Bad artists copy. Good artists steal.”
– Pablo Picasso
It was bound to happen. In the ultra-connected world, things are bound to feed off of each other, eventually erasing differences, equalizing any differential in electric potentials between any two points. No wonder the weirdest animals can be found on islands (I am looking at you, Australia). On the internet, there are no islands, just a constant primordial soup bubbling with ideas.
The refactoring of monolithic applications into distributed systems based on micro-services is slowly becoming ‘a tale as old as time’. They all follow a certain path which kind of makes sense when you think about it. We are all impatient, reading the first few Google search and Stack Overflow results ‘above the fold’, and it is no coincidence that the results start resembling majority rule, with more popular choices edging out further and further ahead with every new case of reuse.
Luke Wroblewski of Mobile First fame once said that ‘two apps do the same thing and suddenly it’s a pattern’. I tend to believe that people researching the jump into micro-services read more than two search results, but once you see certain choices appearing in, say, three or four stories ‘from the trenches’, you become reasonably convinced to at least try them yourself.
If you were so kind as to read my past blog posts, you know some of they key points of my journey:
- Break down a large monolithic application (Java or RoR) into a number of small and nimble micro-services
- Use REST API as the only way these micro-services talk to each other
- Use message broker (namely, RabbitMQ) to apply event collaboration pattern and avoid annoying inter-service polling for state changes
- Link MQ events and REST into what I call REST/MQTT mirroring to notify about resource changes
Then this came along:
As I was reading the blog post, it got me giddy at the realization we are all converging on the emerging model for universal micro-service architecture. Solving their own unique SoundCloud problems (good problems to have, if I may say – coping with millions of users falls into such a category), SoundCloud developers came to very similar realizations as many of us taking a similar journey. I will let you read the post for yourself, and then try to extract some common points.
Stop the monolith growth
Large monolithic systems cannot be refactored at once. This simple realization about technical debt actually has two sub-aspects: the size of the system at the moment it is considered for a rewrite, and the new debt being added because ‘we need these new features yesterday’. As with real world (financial) debt, the first order of business is to ‘stop the bleeding’ – you want to stop new debt from accruing before attempting to make it smaller.
At the beginning of this journey you need to ‘draw the line’ and stop adding new features to the monolith. This rule is simple:
Rule 1: Every new feature added to the system will from now on be written as a micro-service.
This ensures that precious resources of the team are not spent on making the monolith bigger and the finish line farther and farther on the horizon.
Of course, a lot of the team’s activity involves reworking the existing features based on validated learning. Hence, a new rule is needed to limit this drain on resources to critical fixes only:
Rule 2: Every existing feature that requires significant rework will be removed and rewritten as a micro-service.
This rule is somewhat less clear-cut because it leaves some room for the interpretation of ‘significant rework’. In practice, it is fairly easy to convince yourself to rewrite it this way because micro-service stacks tend to be more fun, require fewer files, fewer lines of code and are more suitable for Web apps today. For example, we don’t need too much persuasion to rewrite a servlet/JSP service in the old application as a Node.js/Dust.js micro-service whenever we can. If anything, we need to practice restraint and not fabricate excuse to rewrite features that only need touch-ups.
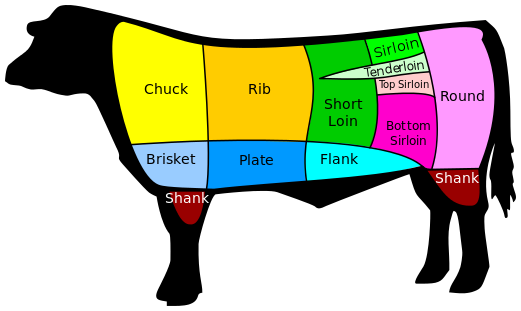
An important corollary of this rule is to have a plan of action ahead of time. Before doing any work, have a ‘cut of beef’ map of the monolith with areas that naturally lend themselves to be rewritten as micro-services. When the time comes for a significant rework in one of them, you can just act along that map.
As is the norm these days, ‘there’s a pattern for that’, and as SoundCloud guys noticed, the cuts are along what is known as bounded context.
Center around APIs
As you can read at length on the API evangelist’s blog, we are transforming into an API economy, and APIs are becoming a central part of your system, rather than something you tack on after the fact. If you could get by with internal monolith services in the early days, micro-services will force you to accept APIs as the only way you communicate both inside your system and with the outside world. As SoundCloud developers realized, the days of integration around databases are over – APIs are the only contact points that tie the system together.
Rule 3: APIs should be the only way micro-services talk to each other and the outside world.
With monolithic systems, APIs are normally not used internally, so the first APIs to be created are outward facing – for third party developers and partners. A micro-service based system normally starts with inter-service APIs. These APIs are normally more powerful since they assume a level of trust that comes from sitting behind a firewall. They can use proprietary authentication protocols, have no rate limiting and expose the entire functionality of the system. An important rule is that they should in no way be second-class compared to what you would expose to the external users:
Rule 4: Internal APIs should be documented and otherwise written as if they will be exposed to the open Internet at any point.
Once you have the internal APIs designed this way, deciding which subset to expose as public API stops becoming a technical decision. Your external APIs look like internal with the exception of stricter visibility rules (who can see what), rate limiting (with the possibility of a rate-unlimited paid tier), and authentication mechanism that may differ from what is used internally.
Rule 5: Public APIs are a subset of internal APIs with stricter visibility rules, rate limiting and separate authentication.
SoundClound developers went the other way (public API first) and realized that they cannot build their entire system with the limitations in place for the public APIs, and had to resort to more powerful internal APIs. The delicate balance between making public APIs useful without giving out the farm is a decision every business need to make in the API economy. Micro-services simply encourage you to start from internal and work towards public.
Messaging
If there was a section in SoundCloud blog post that made me jump with joy was a section where they discussed how they arrived at using RabbitMQ for messaging between micro-services, considering how I write about that in every second post for the last three months. In their own words:
Soon enough, we realized that there was a big problem with this model; as our microservices needed to react to user activity. The push-notifications system, for example, needed to know whenever a track had received a new comment so that it could inform the artist about it. At our scale, polling was not an option. We needed to create a better model.
We were already using AMQP in general and RabbitMQ in specific — In a Rails application you often need a way to dispatch slow jobs to a worker process to avoid hogging the concurrency-weak Ruby interpreter. Sebastian Ohm and Tomás Senart presented the details of how we use AMQP, but over several iterations we developed a model called Semantic Events, where changes in the domain objects result in a message being dispatched to a broker and consumed by whichever microservice finds the message interesting.
I don’t need to say much about this – read my REST/MQTT mirroring post that describes the details of what SoundCloud guys call ‘changes in the domain objects result in a message’. I would like to indulge in a feeling that ‘great minds think alike’, but more modestly (and realistically), it is just common sense and RabbitMQ is a nice, fully featured and reliable open source polyglot broker. No shocking coincidence – it is seen in many installations of this kind. Let’s make a rule about it:
Rule 6: Use a message broker to stay in sync with changes in domain models managed by micro-services and avoid polling.
All together now
Let’s pull all the rules together. As we speak, teams around the world are suffering under the weight of large unwieldy monolithic applications that are ill-fit for the cloud deployment. They are intrigued by micro-services but afraid to take the plunge. These rules will make the process more manageable and allow you to arrive at a better system that is easier to grow, deploy many times a day, and more reactive to events, load, failure and users:
- Every new feature added to the system will from now on be written as a micro-service.
- Every existing feature that requires significant rework will be removed and rewritten as a micro-service.
- APIs should be the only way micro-services talk to each other and the outside world.
- Internal APIs should be documented and otherwise written as if they will be exposed to the open Internet at any point.
- Public APIs are a subset of internal APIs with stricter visibility rules, rate limiting and separate authentication.
- Use a message broker to stay in sync with changes in domain models managed by micro-services and avoid polling.
This is a great time to build micro-service based systems, and collective wisdom on the best practices is converging as more systems are coming online. I will address the topic of APIs in more detail in one of the future posts. Stay tuned, and keep reading my mind!
© Dejan Glozic, 2014

these are nice rules, great work !
what is your point of view about GUIs ?
I think this is an under considered topic and I do not find articles or blogs about it …
Here is a concrete example : to loan a book in a library, you need to scan the user barcode (this step may imply lots of problems like out of date subscriptions, user need to pay a fee, user may have forgotter her umbrella previously, you need to display the current loans, etc…) then you need to scan the book barcode (again, multiple problems to be handled like “hey this is strange because this book is registered as loaned to another user”) and finally the loan is registered.
All that must happen under 500ms…
Microservices are :
$ user services (it knows about the user from the barcode)
$ subscription services (it knows about subscriptions the user is allowed to use)
$ debt services (it knows about the debts of the user)
$ book services (it knows about the book from the barcode)
$ loan services (it knows about exisitng loans and how to do a new one)
How do you implement such a GUI ?
Does it talk directly to the correct services ?
Do you create a new microservice whose responsibility is to perfectly fit the GUI (a proxy to the other services) ?
I tend to favor the second approach to avoid too much calls to the services from the GUI t(because it is impossible to make 10 calls under 500ms in a webapp…) so that in the end the application is a miriasd of small applications working under SSO. What do you think ?
My preference is to create a Web serving micro-service whose job is to render the UI. In order to do so, it will need to call all of the API micro-services. The advantage of this approach is network traffic (service to service traffic will be much faster than browser-to-service), and in some cases you will hit ‘same origin’ problems. Of course, if all your APIs have been proxied by Apache or Nginx to your public URL, you may not hit same origin problems (or you can use CORS).
I also agree that SSO is a crucial pre-condition for this – thank you for calling it out though.